In the first episode of an iconic sci-fi television series decades ago, a NASA test pilot was seriously injured in the crash of an experimental aircraft. The emergency medical team replaced three of Colonel Steve Austin’s four limbs and one eye with nuclear-powered bionic implants, while a voiceover intoned, “We can rebuild him. We have the technology. We can make him better than he was. Better...stronger...faster." During the several seasons of the show, the resulting six-million-dollar-man worked as a secret agent, using his now superhuman powers to battle villains. Since then, science has advanced physical and mental enhancement on many fronts, both to restore normal function for the disabled and to enhance human performance.
The Constant Challenge of Too Much to Translate
Let’s consider language professionals that battle some other villains – translators and interpreters work hard to eliminate linguistic obstacles to understanding essential information in daily life, commerce, politics, health and safety, and every other sphere of human life. The problem is fundamental – there’s so much content generated every day that there’s not enough of these super-heroes to keep pace. Our analysis found that:
Just 0.00000008% of the data generated daily is likely to be translated. That’s the volume after we stripped out everything that didn’t need or wasn’t likely to be rendered into other languages. We calculated that percentage by comparing the daily spend for written-language services with the daily deluge of potentially translatable content.
It would take tens of millions of human translators to address the shortfall. That tiny percentage is deceptive – that daily translation volume might involve as little as one or a few languages, much less the 14 that account for 90% of online business. It rarely encompasses everything that should be translated – we find on multilingual websites that little more than a few percent of the source content is ever translated. Of course, it typically excludes all but a few dozen of the roughly 3,900 languages that have writing systems and all the other previously untranslated but potentially useful gazillions of bytes of content generated digitally and in the dead-tree centuries of publishing that preceded computers.
The Solution – Human or Machine?
It won’t be one or the other, but a combination of the two. Why? There aren’t enough human translators to do it all, and machine translation still isn’t ready for prime time in many applications:
Numbers argue against a purely human solution. There aren’t tens of millions of professional translators available to take up the challenge – figure instead on a few hundred thousand. We should note that there’s a herd of elephants circling this discussion, so let’s add another complication to the calculus – many translators are generalists who aren’t qualified to deal with most specialized domains such as life sciences, finance, mining, or texts that reference quantum anything, derivatives, or a Riemannian manifold.
Some say the machines are ready to do it all – others say not. Some MT proponents argue that the technology has reached “human parity” – although skeptics note the near homophony with “human parody” – and can thus eliminate the gap. This immodest proposal is debatable and inevitably generates a swift response from academic linguists, professional translators, global markets questioning linguistic accuracy, domain applicability, fluency, consistency, lexicon, cultural nuance, relevancy, branding, and a host of other troublesome measures.
Meeting the need requires a range of approaches, including human-machine symbiosis. The reality is that most LSPs already use some MT in their workflows, thus dropping their cost and speeding up production. Some develop MT engines that, for particular applications, produce output that is of sufficient accuracy, fluency, and quality for human consumption. Commercial and government organizations that can segment their translation needs according to absolute needs for humans versus acceptance of MT output will net many more translated bytes than those stuck on human translation only.
Seven Technologies in Search of Adoption
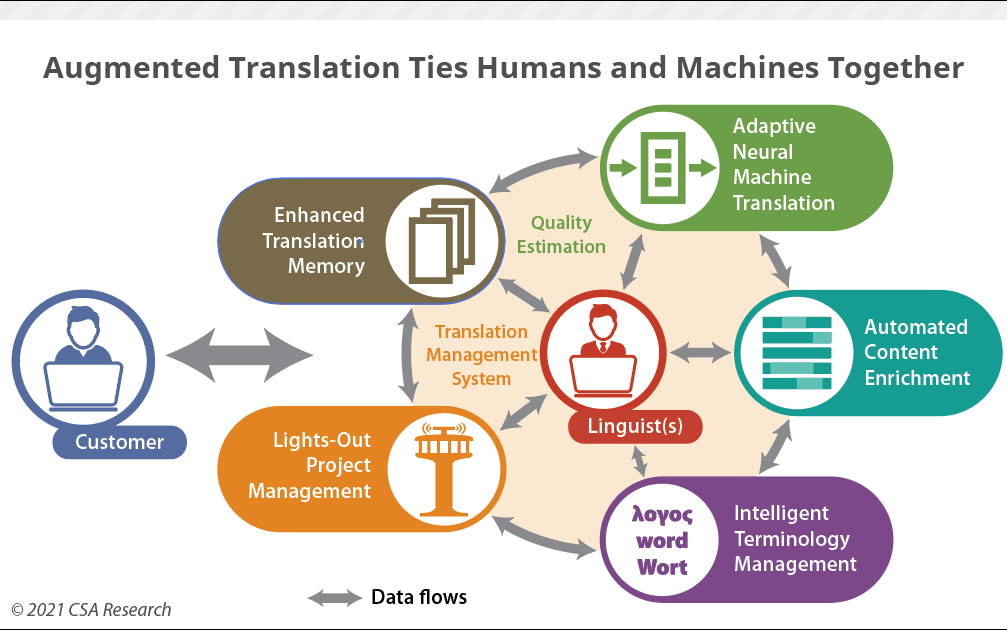
Seven technologies, most of them driven by machine learning, can enhance the capabilities of translators. In 2017 we isolated “augmented translation,” a machine-driven but human-centric approach in which linguists work directly with MT and an array of other technologies that support them, but that leaves them in charge. Based on the innovation of adaptive neural MT, it allowed humans to participate in the real-time, on-line training of neural engines. Rather than position the professional translator in the reactive position of cleaning up after a machine, it put them right in the middle of the training exercise.
Here are the seven language technologies that will enhance human translator performance at the same time they cement the central role of specialists in the process. Each of these langtech offerings augment translator capabilities on their own, but in aggregate improves the content as well. The net effect will be more intelligent source and target content, produced by humans and machines in greater harmony than in today’s post-editing sweatshops.
The accelerator: Adaptive neural MT. Uses neural network technology to produce better quality MT from suggestions by professional translators and learns on the fly from them to produce better-quality output. This technology eliminates the need for comprehensive, periodic retraining in favor of constant micro-updates to ensure that the system improves from corrections. The first wave of AI-enabled CAT tools came to market in 2016 from software developers LILT and SDL, and have since been joined by others, including MateCat, which applies technology from the ModernMT project to enable adaptive capabilities.
The bridge: Translation memory (TM). Records segments and phrases that have been previously translated and provides the target text for use by the linguist. The boundary between TM and MT will blur, especially as these combined technologies provide subsegment matches and performs basic natural language processing techniques to improve its outcomes. TMs, supercharged by adaptive MT and machine learning, will become the repository of record that supports multiple MT and other language solutions. SDL Trados puts some of these capabilities in the hands of the vast majority of linguists, as do offerings from MateCat, MemoQ, and Memsource, to pick just those that start with the letter M.
The platform: Translation management system (TMS). Serves as the platform for range of language, process, workflow, analytic, and participant management. The emerging generation of microservice-based TMSes will serve as the operating system for augmented translation by managing the flows of content and connecting the individual pieces. Linguists will work in translation environments within the TMS and it will in turn deliver the content and resources they need in a just-in-time model. Microservices will enable more agile replacement of components and integration with new repositories (“Translation Management at the Crossroads”). In addition, the TMS is the central repository for data gathering that can support any “small AI” projects that organizations may undertake (“Small AI for Language Technology”). Memsource, SDL, Smartcat, Smartling, TransPerfect, XTM, and others have all developed solutions in this area.
The lexicon manager: Terminology management. Provides approved or suggested translations of terms, including those mined from online resources in real time. Termbases help linguists discover how language is actually used, focus on the translation itself, and avoid time-consuming searches for domain-specific terms. Termbase software will also manage microcontent, such as branding slogans, boilerplate notifications, graphics, and other multimedia assets. Its traditionally manual approach will be supercharged by machine learning from the data deluge (“TechStack: Terminology Management Tools”). Although the terminology discovery pieces are still in the laboratory, Interverbum and Kaleidoscope have both made significant inroads to manage this content and Coreon provides tools to build custom knowledge graphs.
The director: Lights-out project management. Analyzes content to direct jobs to the best human and machine resources based on past performance, the characteristics of the content, the availability of linguists, and the demands of particular tasks. Besides offloading tedious but essential tasks from human project managers, it benefits linguists by eliminating administrative tasks, reducing dependence on inefficient communication methods such as emails, and managing invoicing and payments. As part of a full-fledged TMS, lights-out approaches can handle the selection of TM, MT, and terminology resources and make them available automatically.
The adjudicator: Quality estimation. Provides a statistical estimate of how likely it is that segments of raw MT output have been translated correctly and are readable. This emergent technology operates independently of the adaptive MT engine’s own scoring, so it provides the TMS with a valuable “second opinion” that it can use in determining which translation candidates to show to the linguist. The same principle applies, to a lesser extent, to results from translation memory and to translations that a linguist submits. If quality estimation raises a concern about a segment, it can direct the linguist or a reviewer to pay more attention to the problematic chunk. .
The Encyclopedia Galactica: Automated content enrichment (ACE). Identifies words, concepts, names, dates, and other “entities.” Going beyond traditionally passive terminology management, ACE embeds links to online information about them, including recommended translations, definitions, organization-specific data, locale-specific details, and other contextual information that can save translators a lot of research time. Such intelligent tagging systems have existed since the mid-2000s, but adoption has been slow. One of the first entrants was Refinitiv (né OpenCalais), which adds links to information about people, events, and topics mentioned in text. The European Commission-funded FREME project developed APIs for translation-oriented ACE. Linguists tasked with translating ACE-enhanced intelligent content begin the job with basic research already sitting in the source file, particularly when the terminology management piece is done right.
Technologies Enhance Translators Rather Than Annoy Them
No current software developer provides all of the components of this vision for augmented translation, and it is unlikely any single company could deliver all of them anytime soon on its own. Nevertheless, CSA Research expects that microservice-based TMSes will allow langtech and content management software vendors to develop products with these augmenting technologies and snap them together into seamless experiences for translators. In concert they will put human specialists where they add the most value in the translation process and make them more efficient – better…stronger…faster.
CSA Research materials are copyrighted and provided solely to authorized users.
You are prohibited from submitting any CSA Research content to
generative AI tools, machine-learning systems, public or shared platforms, or any service
capable of storing, training on, or redistributing the material. You may not copy, record,
share, translate, or upload any portion of this content beyond your licensed rights
Unauthorized use, disclosure, or distribution may violate applicable laws. For
permissions or to report misuse, contact legal@csa-research.com.
We use cookies and similar tracking technologies to analyze site traffic and understand how you interact
with our website. This includes using tools to capture behavioral metrics and heatmaps so we can improve our
site design. By clicking 'Accept', you consent to this tracking. You can learn more in our Privacy Policy.