Home > Blogs & Events > Blogs

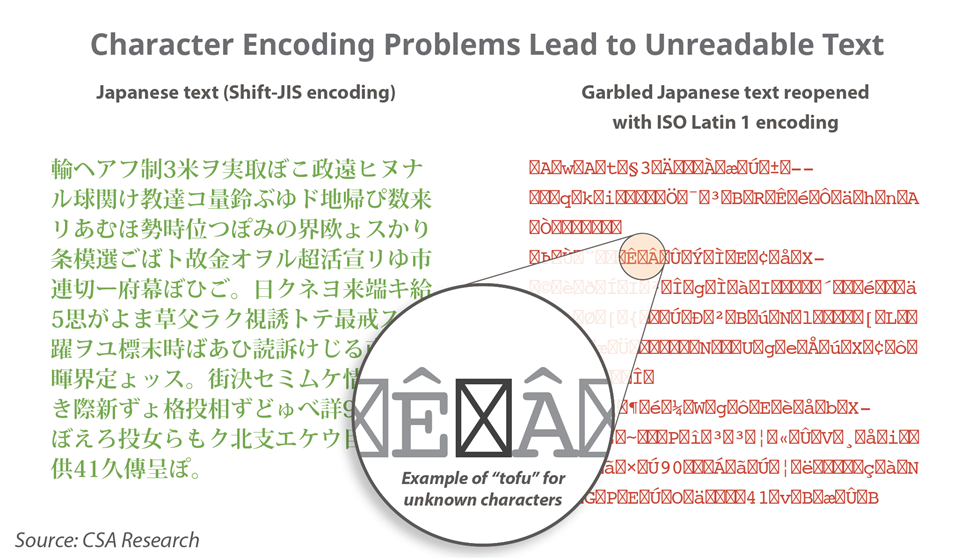
I recently missed an important birthday that everyone in the language industry should have celebrated with fireworks and music. In October 1991, Unicode 1.0 was first released. In the 30 years since that publication an entire generation of language workers have been educated and started work, never having had to know the “joys” of trying to ungarble text that had gone through multiple encodings. I have no nostalgia for the days when LSPs had to hire an engineer just to deal with text encoding or when projects came back because someone’s résumé on Windows had turned into their rÈsumÈ on a Mac or a German name like Müller turned into M□ller with no warning. And if your internet content happened to pass through a seven-bit gateway, the loss might have been unrecoverable.
Those who have entered the language industry since the days when my beard was still red may not be familiar with the little boxes – colloquially known as “tofu” – that appear when software doesn’t recognize a character. They have come of age in a world fundamentally better than the one I started out in. They are used to text just working and to phones that can easily switch between dozens of languages with different writing systems without any trouble.
Prior to Unicode, if you wanted to use a different writing system, you would switch to a different font that supported it. For example, someone working with Old Church Slavonic might create a font where ꙁ is stored in the slot for “z” and ꙗ is stored as “q”. Because these fonts were made to support specific projects and purposes, different people would come up with different approaches and keyboard mappings, ensuring that data was tied to specific fonts and could not be shared with anyone using a different font or approach – at least not without considerable difficulty. It also meant that natural language processing tools could not reliably know what content was represented or intended. Many lifetimes of effort still sit in dusty boxes of diskettes that cannot be read because nobody has the appropriate font today.
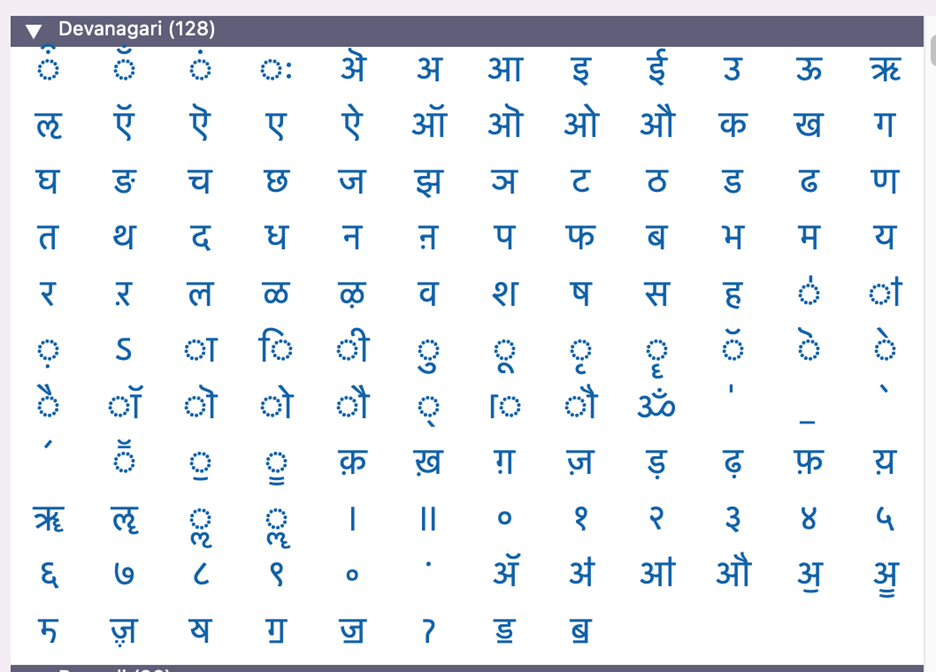
Devanagari character picker in PopChar X, a commercial tool for inserting Unicode characters in text.
Double-byte character sets – such as Big5 and GBK for Traditional and Simplified Chinese respectively – were even more complex and most applications simply failed to render languages that used them (such as Japanese, Korean, and Chinese) or required specialized work-arounds, such as one system I used in 1996 that allowed you to type in Chinese but rendered it by switching between hundreds of single-byte fonts that each contained some portion of the Chinese character set. As I learned the hard way, a single change of font in this system could easily ruin all of a day’s work, so I saved frequently under different names so I could always roll back to a recent version.
In the late 1990s I had a job editing linguistic research papers. I typically spent about 40% of my time in this job tweaking fonts in FontLab and dealing with special character needs, all because Quark Xpress didn’t support Unicode. Then in August 1999, Adobe InDesign 1.0 came out and I switched to it and never looked back. Overnight that 40% of my work became about 5%. And then it became 1–2% as Unicode-rich fonts came out and I no longer had to kludge fonts or work with fine grained character attributes to represent characters like ǘ or ǟ. Eventually it became 0% for the last few times I worked in that field in the late 2010s because Unicode had improved so much. I probably owe the creators of InDesign and Unicode at least a lifetime supply of the beverage of their choice because their efforts have saved me months of my life.
However, as much as I am indebted to Unicode, its most meaningful contribution has not been in saving me hundreds of hours of work. Instead, it has been in enabling people around the world to enter the digital era. As of July 21 (Unicode 14), the specification provides standard encodings for 93 modern scripts (writing systems) and 66 historic or ancient ones, with specializations for many languages. Speakers of hundreds of languages can represent their words in digital format because of Unicode. CSA Research now tracks 130+ languages with significant economic and cultural activity on the web, and hundreds of others appear at lower levels of usage. Many or most of these would not exist online were it not for Unicode.
So, raise a glass in honor of thirty years of Unicode if you remember the bad old days when you had an engineering named Kevin in a back room who spent his days and nights fixing encoding problems. Raise it if you don’t remember those days just because you won’t have to know what that was like. Raise it if you can use your native language online and it isn’t originally from a few countries in Western Europe. Or finally, if you work with and love languages and communication across borders, thank the countless individuals who have contributed their time and effort to developing and expanding Unicode.
Learn how Automated Quality Estimation and Automated Post-Editing redefine translation efficiency and accuracy.
Explore The Report
Access exclusive data, reports, and analyses that power smarter decisions across the global content industry.
Visit the platformAfter obtaining a BA in linguistics in 1997, I began working for the now-defunct Localization Industry Standards Association (LISA), where I headed up standards development and worked on quality assessment models. At the same time, I completed a...
Connect with Arle Lommel
Our consulting team helps you apply CSA Research insights to your organization’s specific challenges, from growth strategy to operational excellence.
Contact our team